Building Power BI models for test purpose requires test datasets. Small tables can be inserted directly in Power BI through the Enter Data user interface


or by using the #table() function in Power Query, as show in the Adding a Static Table with Types in Power Query With M Language article

or in DAX, using the DATATABLE() function, as shown in SQLBI’s article Create Static Tables in DAX Using the DATATABLE Function.
When a larger amount of data is needed, we can use external data sources: SQL tables, Excel files, CSV files and so on.
In this article I’m showing a technique to build large random datasets, directly in Power Query, using M language and without the need for any external data source.
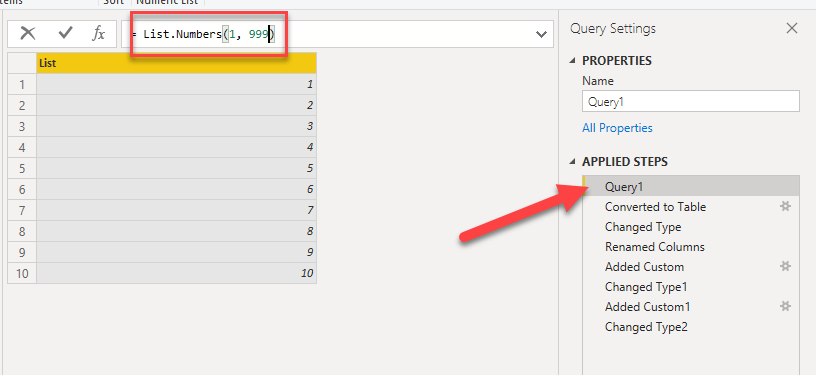
The idea is very simple: starting from the blank query, using the List.Numbers() M function I create a list of integers, then using the Power Query interface “To Table” I transform the list to a table

Since the list just contains numbers, I just accept the defaults and click the OK button

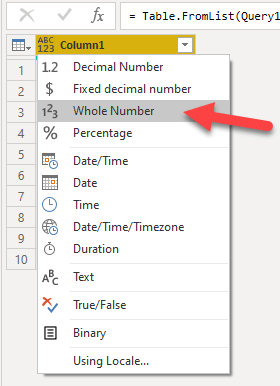
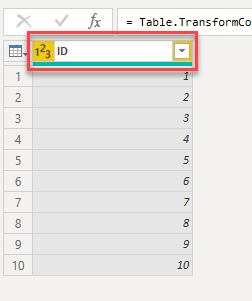
And finally I set the type and the name of the column to Whole Number and ID
Then I can add new custom columns, for instance the fake name of a product by concatenating “Product” and the ID converted to a string


The Number.ToText() function can take an optional format specifier. In this case I formatted the ID to be a three digit number with leading zeroes.
"Produdct" & Number.ToText([ID], "000")Last I selected Text for the column type

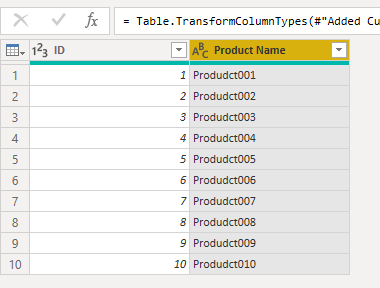
The final result shows the fake product names
To generate random data we can use the Number.Random() and Number.RandomBetween() functions. Sadly, they don’t accept a seed parameter, therefore using these functions it’s not possible to generate the same dataset twice. When this is an issue, the List.Random() function can be used instead.
For instance we can generate a Price column with random values in a range from 1 to 5 dollars with two decimals by creating a new custom column like before, but using the following M expression
Number.RandomBetween(100, 500) / 100And this is the result, after selecting Fixed Decimal Type

After adding all the desired custom columns we can generate as many rows as needed just by changing the Number.List() parameters
And after renaming the query to Fake Products

I can finally close Power Query Editor to load the data into the Power BI dataset

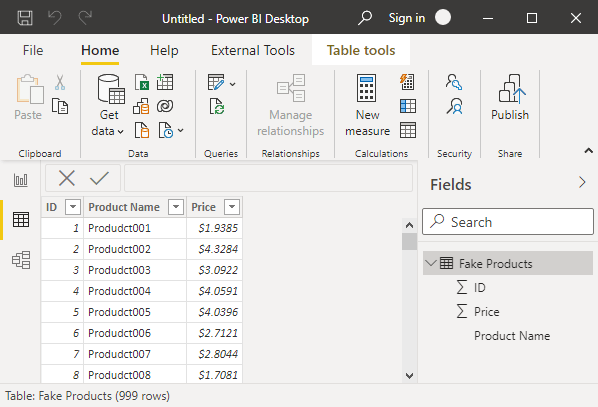
A larger dataset
Using this technique, I was able to change the large model from my previous article Loading 1.6 Billion Rows Snapshot Table with Power Query to work without the need of the source DB. Also, since I can change the size of the dataset at will, I can now share it with a small dataset, that can be made great as you please after the download.
As a starting point I used the template file from my former article HeadCount snapshot M – big.pbit, then I changed the M code in the Employees query using the technique show before.
I also added a few parameters to better control the dataset generation
- EmployeeMaxNumber [Number]: the total number of fake employees to be generated
- FirstDate [Date]: the lower bound for the hire and leave dates
- LastDate [Date]: the upper bound for the hire and leave dates
- MinimumDays [Number]: the minimum days of stay
- LeaveProbability [Number]: the probability that the employee left (from 0 to 1)
The M code to generate a random date requires the conversions from Date to Number and vice-versa
Date.From(Number.RoundDown(Number.RandomBetween(Number.From(FirstDate), Number.From(LastDate)))))Since I changed the date range I also had to apply a few minor changes to M code for the Employee Snapshot table and to the DAX code for the Date table.
Setting EmployeeMaxNumber to one million, I generated a snapshot table around 1.7 billion rows. This number can vary, since it’s a function of the random generated dates.
Conclusions
Power Query can be used to generate test datasets as large as needed thanks to the List.Numbers(), Number.Random() and Number.RandomBetween() M functions.
The sample pbix files for this article can be downloaded from my shared github project.
