In this post I’m showing how to create random data with Power Query that doesn’t change when a refresh operation happens.
In my previous post Loading Large Random Datasets with Power Query I used Number.Random() and Number.RandomBetween(), that generate a different random number each time they are called.
The consequence is that each time we refresh the dataset we get a new set of random values, and therefore it is impossible to check the consistency of the results we get by our measures after a modification in Power Query triggers a refresh operation.
A solution is to use the List.Random() function, that returns a list of random numbers and has an optional seed parameter. When the same seed is specified, List.Random() returns the same list of random values.
But List.Random() returns a list of numbers and therefore cannot directly replace Number.RandomBetween() in the code shown in the previous post: first we have to generate the list with all the random numbers we need and then we must access the list taking the random number at the right index.
Last but not least, the Number.RandBetween() generates a number in the specified range and List.Random() instead generates a list of numbers between 0 and 1, so we must also change the code that computes the final value.
The signature of List.Random() is
List.Random(count as number, optional seed as nullable number) as listSo we must specify the number of random numbers to be generated as the count parameter and the seed to be used.
In our example the count is the same value used to generate the list of indexes, that is the length of the Fake Product table.
The seed can be any value, its only purpose is to make the generated random numbers list to be the same across refreshes. Changing the seed can be useful to check the resulting model using different values.
Since the same length value is to be used in two different places, I created a parameter called NumberOfProducts
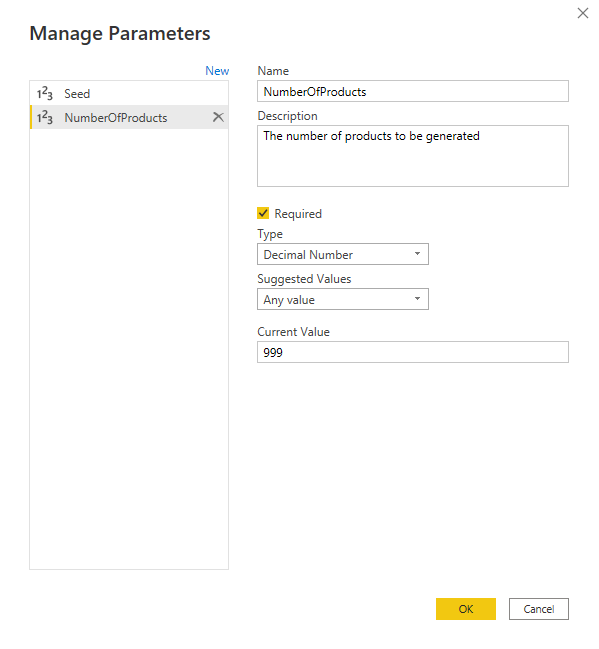
I also created a parameter called Seed to be used as the seed
Therefore the code to generate the list of random values and the list of indexes becomes
RandomList = List.Random(NumberOfProducts, Seed),
IndexList = List.Numbers(1, NumberOfProducts),and the code to access the RandomList at the index corresponding to the line becomes
RandomList{[ID] - 1}the curly braces are used to access the list at the specified index, and the ID between the square brackets refers to the ID column in the current table row. Then, since lists are zero based and the ID index instead is starting at 1, we need to subtract 1 from the ID.
After the changes, the final code for the Fake Products table is
let
RandomList = List.Random(NumberOfProducts, Seed),
IndexList = List.Numbers(1, NumberOfProducts),
#"Converted to Table" = Table.FromList(IndexList, Splitter.SplitByNothing(), null, null, ExtraValues.Error),
#"Changed Type" = Table.TransformColumnTypes(#"Converted to Table",{{"Column1", Int64.Type}}),
#"Renamed Columns" = Table.RenameColumns(#"Changed Type",{{"Column1", "ID"}}),
#"Added Custom" = Table.AddColumn(#"Renamed Columns", "Product Name", each "Produdct" & Number.ToText([ID], PadNumber)),
#"Changed Type1" = Table.TransformColumnTypes(#"Added Custom",{{"Product Name", type text}}),
#"Added Custom1" = Table.AddColumn(#"Changed Type1", "Price", each Number.Round(RandomList{[ID] - 1} * 4 + 1, 2)),
#"Changed Type2" = Table.TransformColumnTypes(#"Added Custom1",{{"Price", Currency.Type}})
in
#"Changed Type2"Since the number of products is now a parameter, I also had to change the code that computes the name of the product by replacing the format parameter “000” in the Number.ToText() with a string containing a number of zeroes large enough, that is computed as a separated query PadNumber
let
LogNumber = Number.Log10(NumberOfProducts),
Digits = Number.RoundUp(LogNumber),
PadNumber = Text.Repeat("0", Digits)
in
PadNumberThe sample pbix file for this article can be downloaded from github
