The head count for human resources is a rather common request found in Power BI related forums and the usual suggestion is to implement the Events in progress DAX Pattern from SQLBI. I built a sample model to experiment with this pattern.
The problem
The Employee table contains the hire date and the leave date. The leave date is blank if still employed. The request is to count the number of employees (heads) during the selected period of time.
The direct solution
The direct approach to implement the head count measure is to check if the selected period of time intersects the interval between the hire and leave dates. This can be easily implemented with DAX, as shown in the first section of the pattern, but performance is not very good, because the intersection is performed entirely with DAX code and no physical relationship is used.
The snapshot table approach
This approach consists in the creation of a snapshot table, by expanding the interval between the hire and the leave date, creating one row per each day, and then by creating a physical relationship with the Date table on the Date column. Then to create a measure simply by computing the distinct count of the employee IDs.
To my surprise, the performance with this measure in the sample model is worse than the previous one. The reason is that in this scenario the DISTINCTCOUNT needs to iterate on a very large number of rows to count the distinct IDs.
To avoid the DISTINCTCOUNT it’s possible to compute the head count at the end of the selected period instead than over the whole time selection. Because each employee can appear just once per day, it’s possible to use COUNTROWS on the last day to compute the number of employees at he end of the selected period.
This measure performance is very good.
When the selected time period is at the day level, the two measures return the same result, therefore at the day level we can always use the end of period version of the measure.
When the selected time period is at a higher granularity level, the results of the two measures are slightly different, therefore a decision must be made: is it acceptable to use the end of period version of the measure, or is it mandatory to compute the head count using the whole selected time period?
The solution for the latter in the sample model is to check the granularity level to choose the measure to be used dynamically: the end of period one at the day level and the direct solution one at the month or year level.
Conclusion
As usual, each scenario is different and the possible solutions must be tested.
This HR scenario consists of events that lasts for very long. This means that the snapshot table approach of the Events in progress DAX Pattern needs to create a very large snapshot table, since each row in the employee table is multiplied by the number of days of employment.
A performance gain can be obtained using the End Of Period version of the measure with the snapshot table.
By dynamically checking the granularity level it’s possible to choose the measure version to be used.
The sample model builds the snapshot table using DAX. A different approach like using Power Query or SQL could work better in real case scenarios.
Should we always use a snapshot table? Probably not, since the advantage of performance might be less than the cost of building a very large snapshot table, but it depends on the actual data of the real scenario and on the reports to be implemented.
The sample model
The employee table contains about 300K employees over three years, from the 2008 to 2010
To simulate the employee table I used the User table from the Small Stack Overflow Database provided by Brent Ozar on his awesome blog
The query uses the LastAccessDate as LeaaveDate, setting NULL when after the 2010
WITH CTE AS (
SELECT [AccountId]
,[DisplayName]
,CONVERT(DATE, [CreationDate]) AS HireDate
,CONVERT(DATE, [LastAccessDate]) AS LeaveDate
FROM [dbo].[Users]
WHERE Id <> -1 AND Id <> 11
)
SELECT
AccountId AS ID
, DisplayName AS Name
, HireDate
, CASE WHEN LeaveDate > '20101231' THEN NULL ELSE LeaveDate END AS LeaveDate
FROM CTE
The Date table is a very simple DAX calculated table
Date =
ADDCOLUMNS(
CALENDAR(DATE(2008, 1, 1), DATE(2010,12,31)),
"Year", YEAR( [Date] ),
"Year Month", EOMONTH([Date], 0), -- formatted as yyyy-mm
"Month", MONTH( [Date] )
)
The generated Employee table contains about 100K non-blank and 200K blank LeaveDate

The HireDate are distributed rather smoothly from the 2008 to the 2010, as can be seen by the Hires Running Total

The resulting head count grows up to 200K, as expected

The measure [Head Count] uses directly the Employee table. It filters the Employee rows by checking if the selected period overlaps with the time interval between the HireDate and LeaveDate. The REMOVEFILTERS( ‘Date’ ) removes the effect of any existing relationship between the Date and the Employee tables.
Head Count =
VAR FromDate = MIN('Date'[Date])
VAR ToDate = MAX('Date'[Date])
RETURN
CALCULATE (
COUNTROWS( Employee ),
Employee[HireDate] <= ToDate,
Employee[LeaveDate] >= FromDate || ISBLANK(Employee[LeaveDate]),
REMOVEFILTERS('Date')
)The performance of this measure to build the graph over the whole 3 years at the day level granularity can be measured using DAX Studio

This query runs in about 4.5 seconds
The snapshot table approach
To try to improve performance, I implemented the snapshot table as a DAX calculated table
Employee Snapshot =
VAR MaxDate = MAX( 'Date'[Date] )
RETURN
SELECTCOLUMNS(
GENERATE(
Employee,
VAR HireDate = 'Employee'[HireDate]
VAR LeaveDate = IF ( ISBLANK( 'Employee'[LeaveDate] ), MaxDate, Employee[LeaveDate] )
RETURN
DATESBETWEEN(
'Date'[Date],
HireDate,
LeaveDate
)
),
"ID", Employee[ID],
"Date", 'Date'[Date]
)This code expands each row of the Employee table creating one row per each day from the HireDate to the LeaveDate or to the last date of the date table, when LeaveDate is BLANK.
The resulting Employee Snapshot table contains about 68M rows

And then the physical relationship over the Date can be created
The Head Count measure can be implemented by counting the distinct IDs in the current filter context
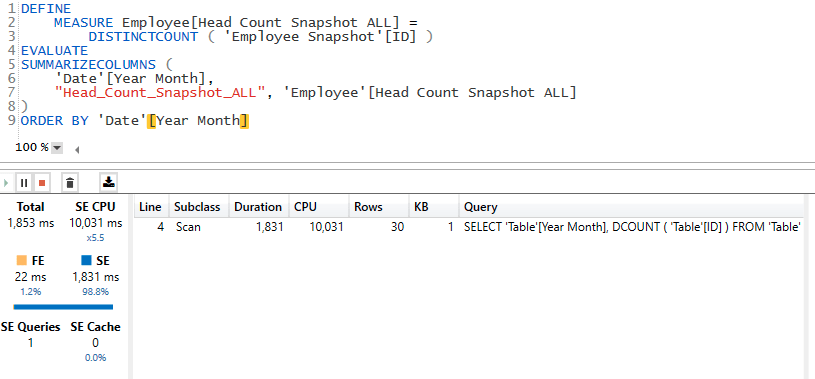
Head Count Snapshot ALL = DISTINCTCOUNT( 'Employee Snapshot'[ID] )But the performance is worse than with the previous measure

The total execution time is now almost 24 seconds! This happens because of the DISTINCTCOUNT.
To get rid of the DISTINCTCOUNT it’s possible to use the faster COUNTROWS to count the rows on the last day of the selected period. This works because each employee ID in the snapshot table appears only once per day. At the day level of granularity there is no difference with the [Head Count] and [Head Count Snapshot ALL], since they all operate on the same time period of one day.
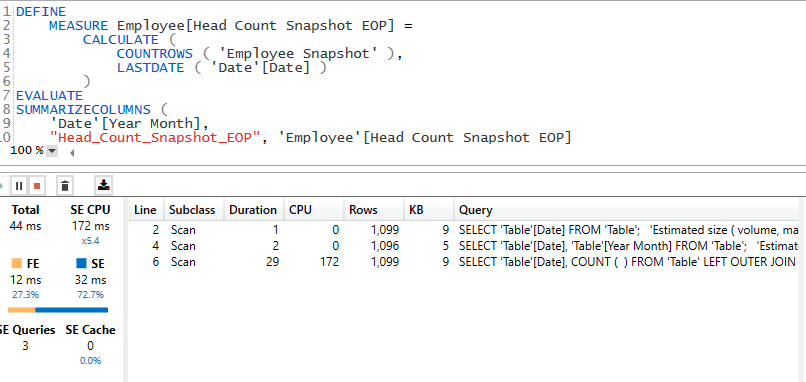
Head Count Snapshot EOP =
CALCULATE (
COUNTROWS ( 'Employee Snapshot' ),
LASTDATE ( 'Date'[Date] )
)This measure performance is way better than the previous ones

The execution time is now just 65 milliseconds!
Let’s see what happens at the month granularity level

As we can see at the month level of granularity the [Head Count] measure performance is good, since it takes just about 160 milliseconds.
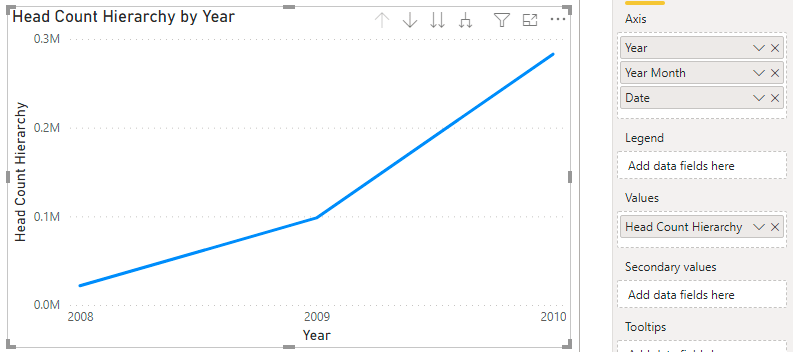
The difference between the [Head Count] and the [Head Count Snapshot EOP] when used at the month level of granularity can be seen in the following graph

To avoid this difference without losing the gain in performance obtained at the day level, it’s possible to check the granularity level dynamically to select the measure to use
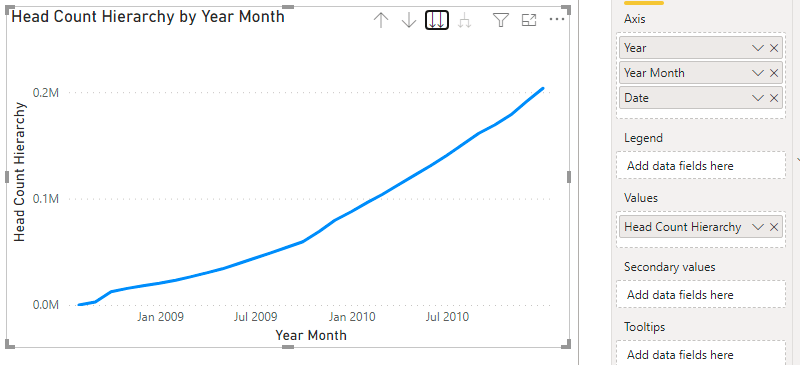
Head Count Hierarchy =
IF (
ISINSCOPE ( 'Date'[Date] ),
[Head Count Snapshot EOP],
[Head Count]
)This way it’s possible to create a graph visual with a hierarchy on the X axis: Year, Year Month and Date

The model and the DAX queries used to compute the performance can be downloaded from GitHub

I’m curious if the performance would be better or worse with a different approach to eliminating the distinction. By simply counting the rows in the employee table instead as they’re already already unique. Filtered with an inactive relationship or treatas (depending on the model).
Count ALL =
CALCULATE( COUNTROWS( Employee ), USERELATIONSHIP ( Employee[ID], ‘Employee Snapshot'[ID]
LikeLike